Technical SEO audit, built for developers
A scriptable, local-first technical SEO crawler for engineers and agencies — 20 analyzers, CLI + MCP, no URL cap, client-NDA safe. Crawl any site, diff against a baseline, export to XLSX or a single self-contained HTML file.
What's in a technical SEO audit?
A technical SEO audit inspects the machinery search engines need to crawl, index and rank a site — robots.txt, redirects, canonicals, sitemaps, hreflang, structured data, page speed, internal link distribution. It sits upstream of content and off-page SEO: if the technical layer is broken, rankings cap out no matter how good the content is.
crawler4seo ships 20 analyzers that cover the full technical surface, a PageRank-weighted internal-link graph, and a CLI for scripting. It runs entirely on your machine — the crawl database is a local SQLite file you own and can delete at any time.
What the technical SEO audit checks
Six analyzer families, running in parallel during a single crawl.
Crawlability
robots.txt compliance, redirect chains (3xx loops + depth), canonical tag consistency, noindex / nofollow audit, URL normalization. The plumbing Google needs before anything else matters.
Indexability & sitemap
Cross-reference /sitemap.xml with crawled URLs. Four buckets: indexable, non-indexable, not-crawled, missing-from-sitemap. Catch pages that exist but Google can't discover.
Schema.org Rich Results
JSON-LD validation with @graph support, per-type eligibility against Google Rich Results rules for Product, Article, FAQ, Recipe, JobPosting and 15+ other types. Per-page failure reasons, not just "invalid schema".
hreflang / i18n audit
Bidirectional reciprocity checks, x-default coverage, <html lang> consistency, cluster drilldown. The audit Screaming Frog only surfaces via paid integration.
Core Web Vitals
Real CrUX field data via PageSpeed Insights: LCP, INP, CLS with Google thresholds. Per-page breakdown, issues auto-created at "needs improvement" and "poor" thresholds.
Internal-link graph
PageRank, HITS (hubs / authorities), connected components, click-depth via BFS. Interactive D3 force graph — see which pages are starved of internal links.
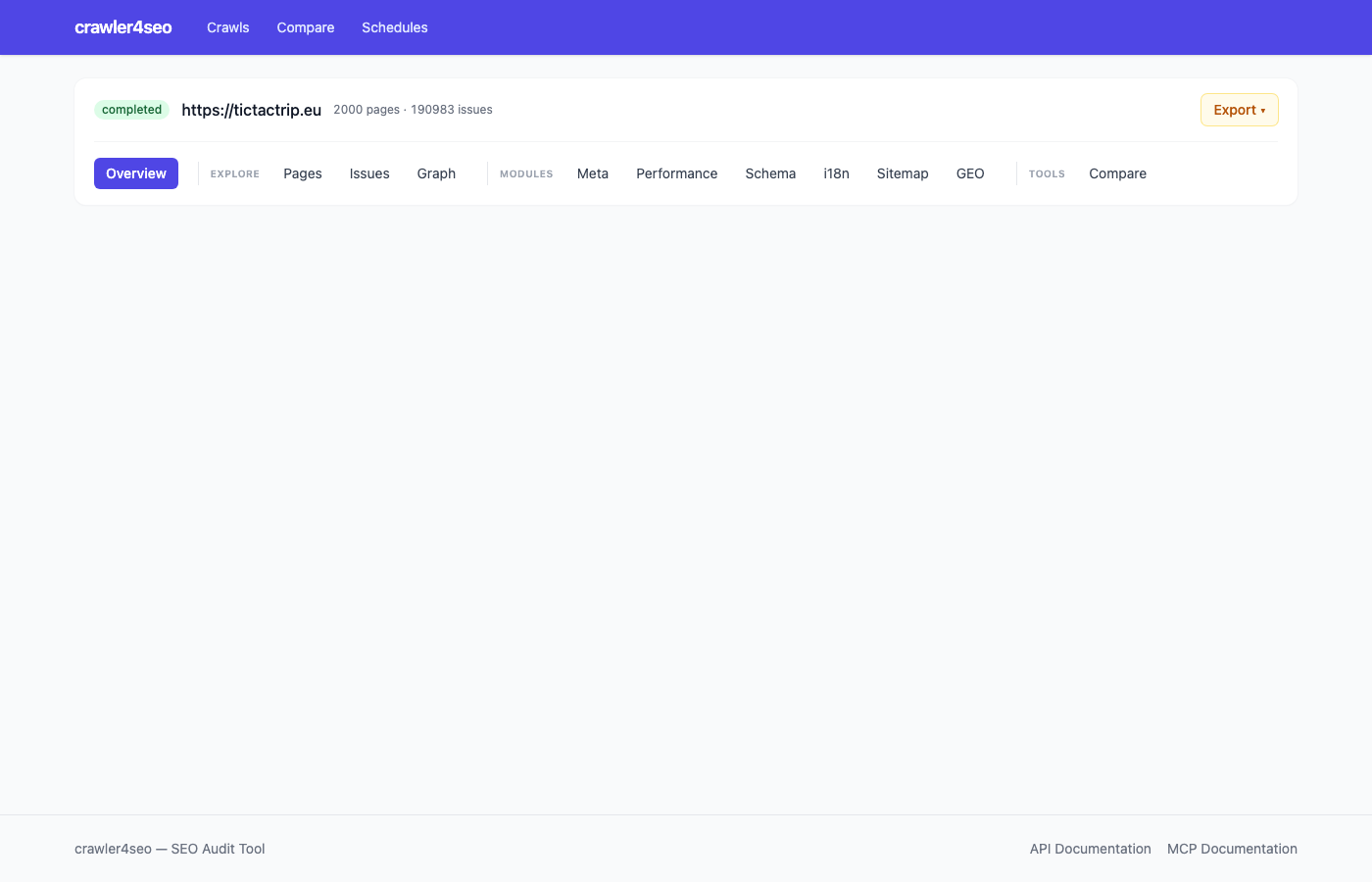
Why dev teams & agencies pick crawler4seo
Six things SaaS crawlers make hard or expensive, that crawler4seo does by default.
100% local — NDA-safe for client audits
Your crawl data lives in a SQLite file on your machine. No cloud upload, no third-party account, no vendor sitting between you and the client's site. Sign an NDA, run the audit, delete the file. Done.
Unlimited URLs on the free tier
No 500-URL cap, no per-URL pricing, no seat fees. Crawl the marketing site or the 500k-URL e-commerce catalog with the same tool — agencies don't need to rewrite pricing per client.
Native MCP server for AI-assisted triage
Point Claude or any MCP client at your crawl: "show me all pages with missing H1 AND PageRank < 0.001" — conversational SEO analysis against the full dataset, in your editor.
Custom CSS / regex extraction per crawl
Define selectors or regex rules before the crawl. Pull prices, author bylines, product SKUs, stock status — anything — into structured columns for the XLSX export.
Crawl diffing for regression tests
Diff two .c4s files: pages added/removed, issues opened/resolved, PageRank shifts. Wire it into staging deploys and catch SEO regressions before they reach production.
Scheduled crawls with regression alerts
Cron-driven monitoring of client sites. Auto-compare each new crawl against the baseline and flag what broke. One instance monitors dozens of client sites in parallel.
Scriptable, end-to-end
Crawl, diff, export — three commands that replace most of a manual SEO audit pipeline.
crawler4seo vs SaaS SEO audit tools
Technical-SEO audit parity, minus the per-URL pricing and cloud lock-in.
| Typical SaaS SEO tool | crawler4seo | |
|---|---|---|
| Per-URL / per-seat pricing | Yes | None — free, unlimited URLs |
| Where data lives | Vendor cloud | Your local SQLite |
| CLI / scriptable | Paid tier only | Shipped |
| MCP / AI integration | Not supported | Native MCP server |
| JavaScript rendering | Paid add-on | Included (Playwright) |
| Crawl diffing | Enterprise tier | .c4s file diff |
| Client-NDA compatibility | Vendor ToS applies | Data never leaves your machine |
Comparing against Screaming Frog, Sitebulb, Netpeak Spider, Oncrawl, JetOctopus and Lumar.
Frequently asked questions
Things people ask before switching.
What does a technical SEO audit cover?+
A technical SEO audit inspects the machinery Google needs to crawl, index and rank a site — robots.txt, redirects, canonicals, sitemaps, hreflang, structured data, page speed, internal linking. It is distinct from content SEO (keyword research, topical authority) and from off-page SEO (backlinks). crawler4seo ships 20 analyzers that cover the full technical surface in one crawl.
Why do agencies and dev teams pick crawler4seo over Screaming Frog, Sitebulb or SaaS?+
Three reasons: (1) crawl data stays on the machine, which makes NDA-bound client work trivial; (2) no URL limit and no seat fee, so the same tool handles a 500-page site and a 500k-URL e-commerce catalog; (3) a native MCP server that lets Claude or any MCP client query the crawl conversationally — useful when triaging a big audit.
Is there really a CLI?+
Yes. crawler4seo ships as both a desktop app (Electron UI) and a CLI that shares the same engine. The CLI is scriptable, ideal for CI-triggered crawls, scheduled audits, and regression diffs against a baseline .c4s file. All commands are documented in the README.
What about JavaScript-heavy sites and SPAs?+
Playwright is embedded, so JS rendering is built in — no paid add-on. The crawler sees the same DOM Google sees. For pages where content only appears after JS execution, the GEO audit also flags them as invisible to AI crawlers (which do not execute JS).
Can I export the audit for a client deliverable?+
Two options. (1) Standalone HTML audit: one self-contained file with the full interactive dashboard — the client double-clicks, it opens in any browser, no install. (2) Multi-sheet XLSX: pages, issues, links, images, structured data, redirects, hreflang, custom extractions, graph metrics. Both exports are free and unlimited.
Is the free tier really free, or is it a trial?+
Free while in early access, with no URL limit and no account. The long-term plan is a paid tier for team features (shared crawl storage, access control) — the core audit will remain free for individual use.
Run your first technical audit in 30 seconds
Download the desktop app or grab the CLI. Paste a URL, hit Start Crawl. No signup, no credit card, no URL cap — and your crawl data never leaves your machine.
Download free